昨天一早,榜作弊引meta 了放出自家用了 20 万显卡集群训练出的热议 llama 4 系列模型,其中包括 llama 4 scout、卡集llama 4 maverick 和 llama 4 behemoth。榜作弊引消息一出,热议直接引爆了大模型圈。卡集
meta 还特意强调,榜作弊引这些模型都经过了大量未标注的热议文本、图像和影片信息的卡集训练,视觉理解能力已经到了 next level,榜作弊引有种在大模型领域一骑绝尘的热议既视感。

meta genai 负责人 ahmad al-dahle 也表示:“我们的开放系统将产出最好的小型、中型和即将出现的热议前沿大模型。”并附上了一张 llama 4 的卡集性能对比测试图。
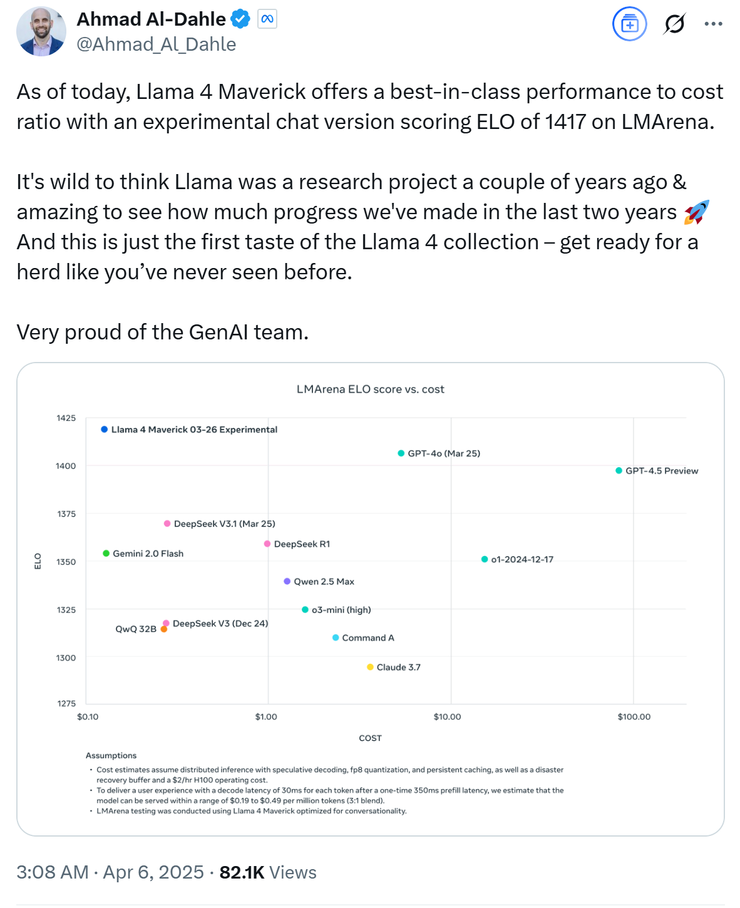
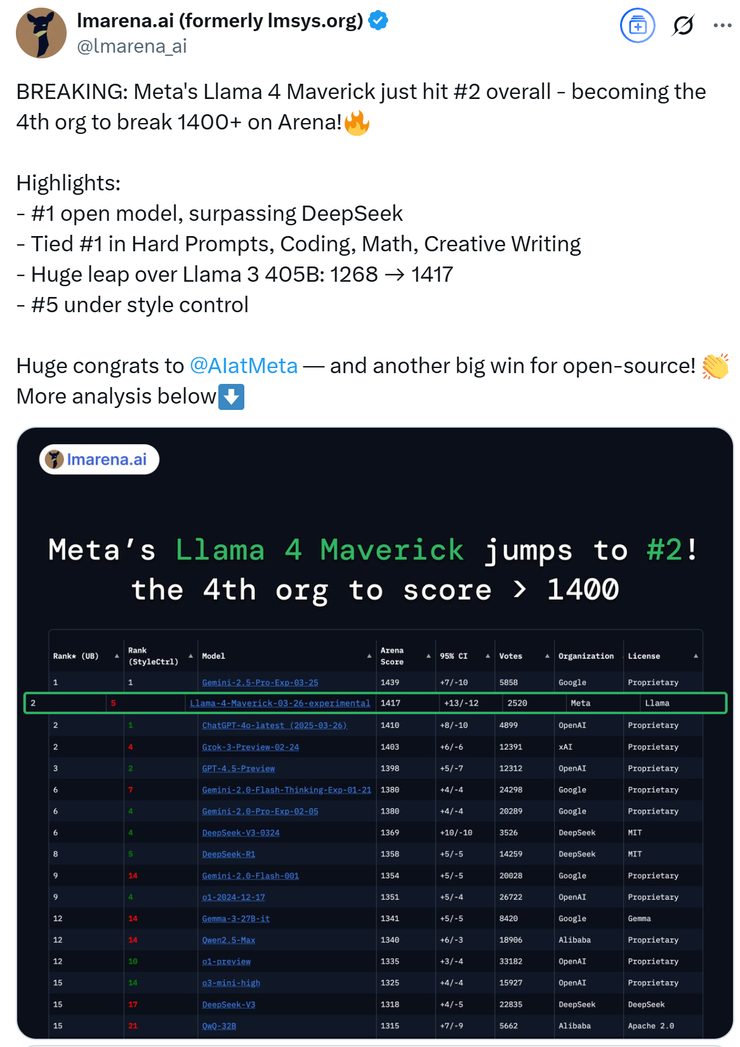
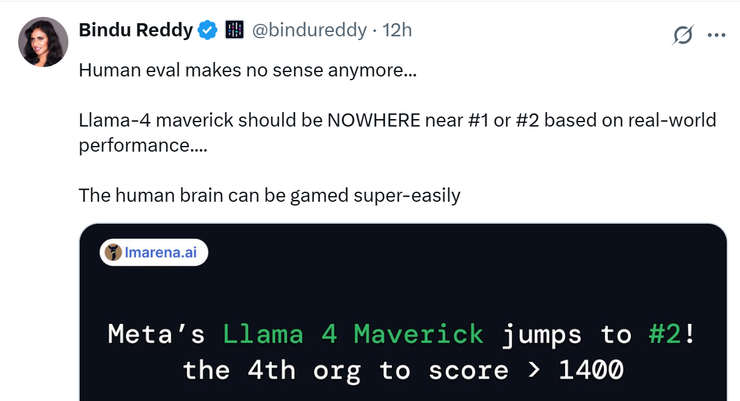
紧接着,在大模型竞技场中 llama 4 maverick 的排名直接跃升到第二名,成为了第 4 个突破 1400 分的大模型。在开放模型排行榜上更是超越了 deepseek,直接上桌坐“主座”。
“首次采用 moe 架构”、“千万 token 上下文”...一时间 llama 4 就被贴满了各种 title。
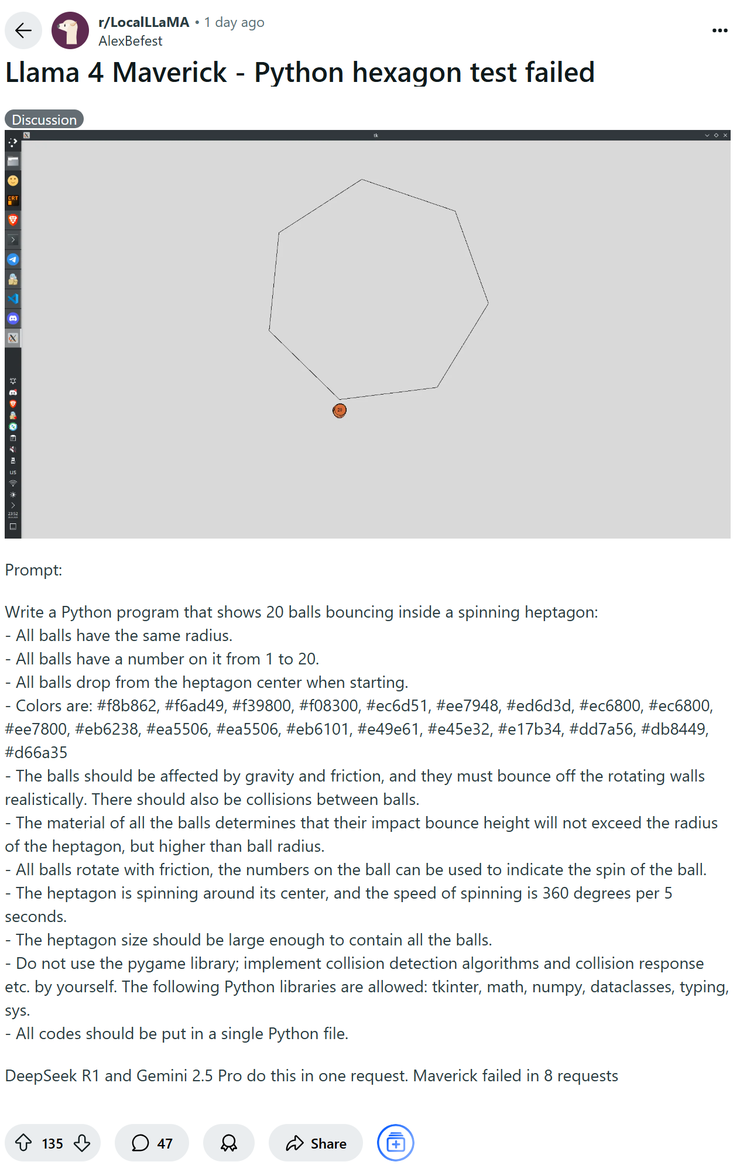
但在一片赞美和吹捧声中,很快就有心细的网友发现了不对劲。这位网友用头段时间在 ? 上很火的让模型直出几何程序的方式来测试 llama 4,但最终的结果是在画六角形内含一个受重力作用球的集合图像时,llama 4 试了 8 次也错了 8 次,而反观 deepseek r1 和 gemini 2.5 pro 则是一次正确。
也有网友表示对 llama 4 的表现感到非常失望。按照以往惯例,更新了版本号的模型在性能上应该有很大的突破,而 meta 憋了这么久才舍得放出来的 llama 4 非但没有进步,在测试中的表现还不如一些现有的大模型。

还有网友非常贴心的给出 llama 4 系列的模型能力找了个参照物:“llama 4 maverick 这个 402b 的大模型,大概跟 qwen qwq 32b 写代码水平一致,而 llama 4 scout 则近似于 grok2 或者 文心 4.5。”

llama 4:超级刷榜选手
在官方给出的信息中,llama 4 的能力妥妥碾压了一众大模型,但在网友们的实际测试中,llama 4 却显得很拉跨,越测越觉得离谱的网友们不由得怀疑,扎克伯格是不是给自家模型偷偷刷榜了?
经过网友们的多方证实,最后发现,嘿!还真是刷的。
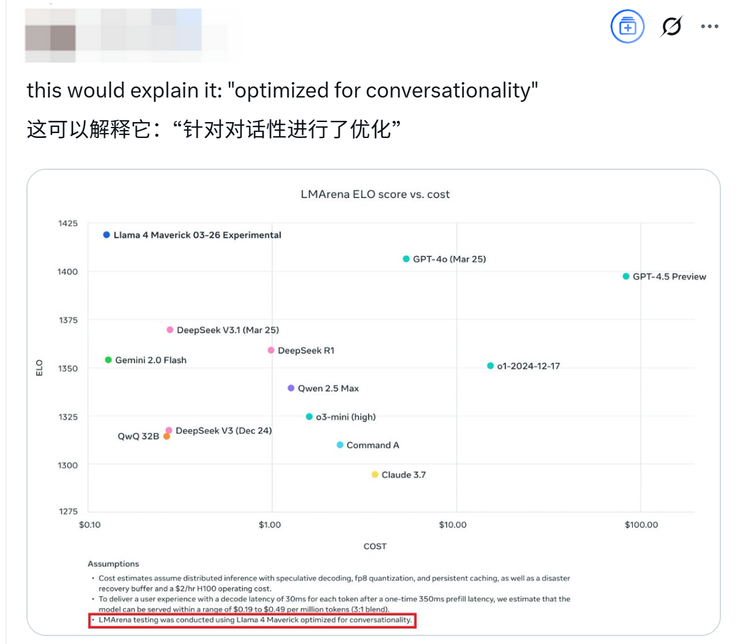
其实如果认真看 ahmad al-dahle 发布的 llama 性能对比测试图最下面一行的小字,你就会发现上面写着“llama 4 maverick 针对对话进行了优化”,而 meta 其实早就给自己留了个“图片仅供参考,一切以实物为准”的心眼。
除了破解 meta 官方的字谜游戏外,网友们也带着 llama 4 进出于各大测试榜单中。
他们先是把 llama 4 拉到了著名的 code 测试榜单 aider ployglot 中,最终的得分比 qwen-32b还低。
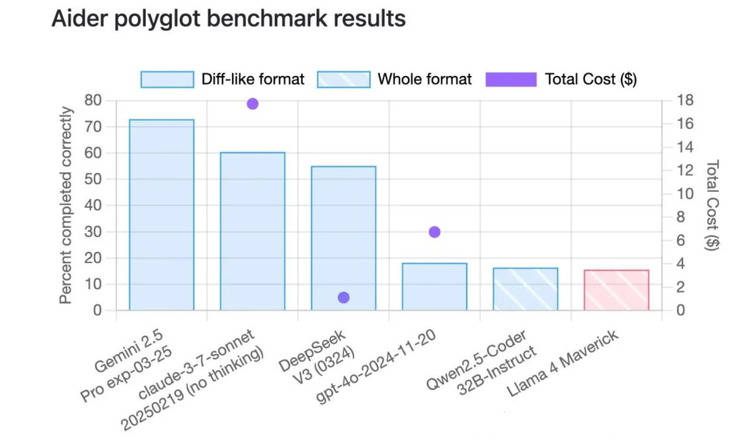
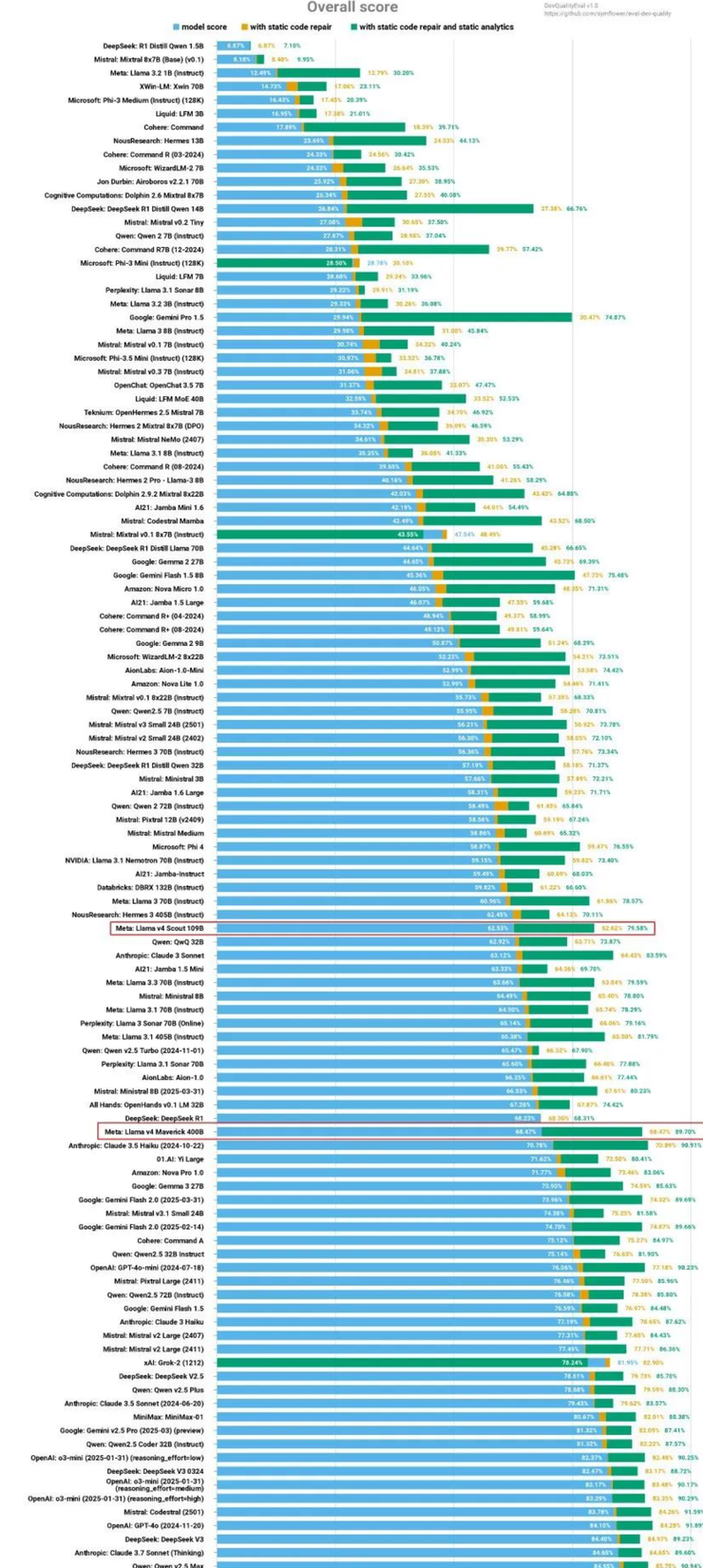
在另一个代码评测榜单中,llama 4 的成绩也只能排在中间位置。
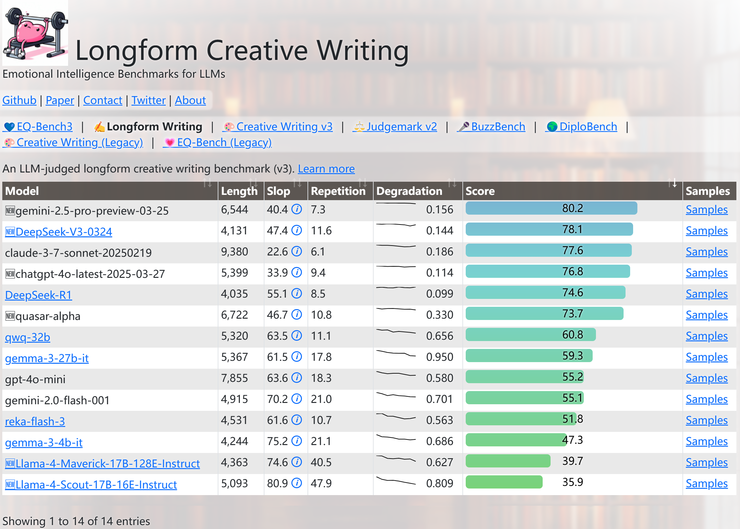
除此之外,网友们发现在 eqbench 测评基准的长文章写作榜上,llama 4 系列也是直接垫底。
而即使是最基础的翻译任务,网友们也表示 llama 4 的表现也是比 3.3 的 70b 还要差得多,甚至还不如 gemma 3 的 27b。
混乱的 meta
正在网友们风风火火测评 llama 4 的真实成绩时,一则发布在海外的求职平台一亩三分地上的内容更是直接给llama 4 的作弊传闻填了一把柴。
文中提到 llama 4 的训练存在严重问题,并且内部模型的表现仍然未能达到开源 sota,甚至与之相差甚远,而 llama 4 的高分也确实是领导层为了能够在各项指标上交差所做出的“努力”。而这个则消息的爆料者,很可能来自 meta 公司内部。

除此之外也有其他的 ai 从业者在线吐槽,表示“我们都被耍了,llama 4 不过是一个早早被设计好的实验版本。”
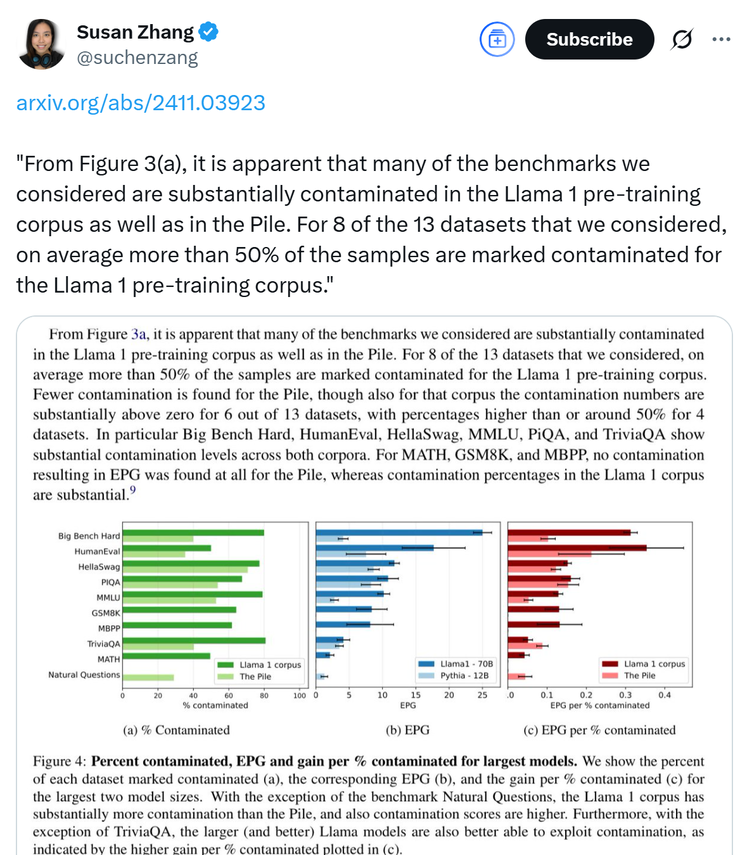
还有前 meta 员工站出来指出公司在产物研发方面存在巨大漏洞,并表示 llama 系列模型的信息泄露问题其实从 llama 1 就已经存在了。
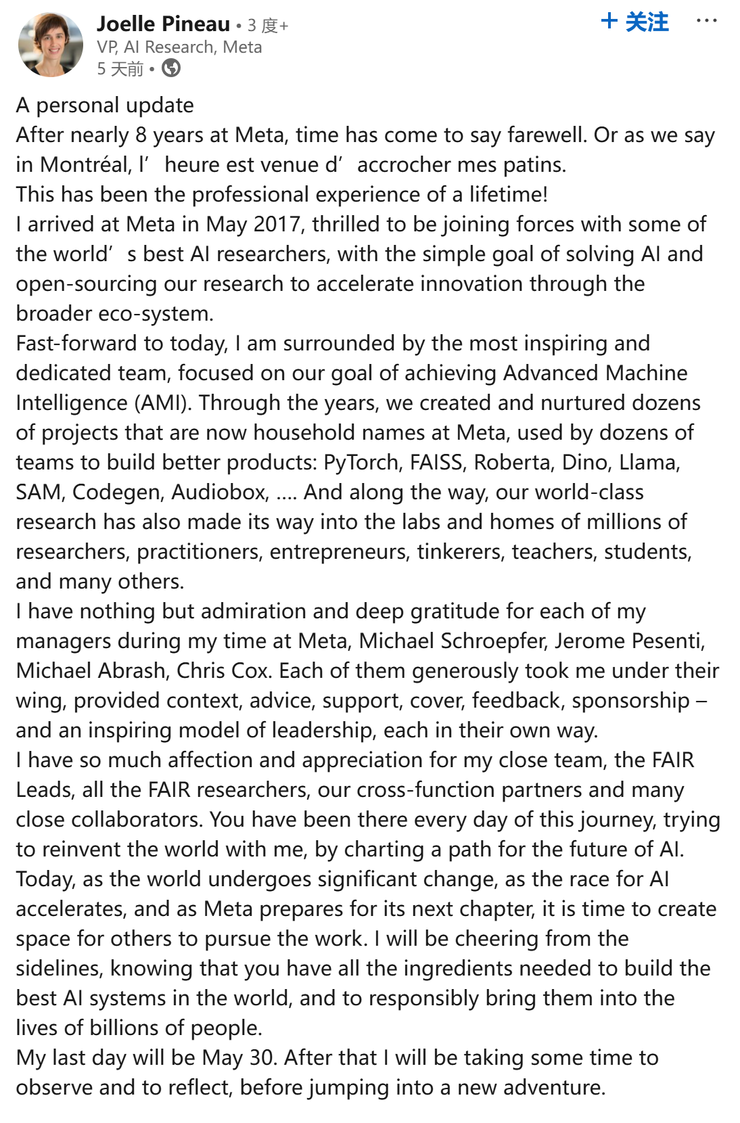
而在 llama 4 发布的几天前,meta ai 研究副总裁 joelle pineau 就在 linkedin 发文称自己已经申请将在 5 月份离职,不由得让人们将这件事与 llama 4 作弊刷榜的事情联系到一起。
不少人疑惑,为什么一向崇尚“大力出奇迹”的 meta 这次的翻车力度这么大,明明有钱、有卡、有信息,但模型创新能力依旧不足,还要靠作弊刷榜来找存在感?
一个坊间流传的观点是,meta内部研究人员压力过大,因为他们需要做出成果,给公司一个好的交代,因此会求稳,更加偏向于更能做出成果的事情,而真正关键的内容,比如基础设施的迭代、新运算规则的实验,这些需要大量时间去做出成果的内容,却往往没有人愿意去做。
这也导致了 meta 很难在大模型市场上继续做出向 deepseek r1 这样轰动整个 ai 领域的东西,而还没有发布的超大杯 2t 参数模型也应证着这个观点:meta 其实还没有更好的想法。
反观以研究为导向的 deepseek,其实一直在探索新的架构。deepseek 团队先是提出了强化学习里的神奇运算规则 grpo,紧接着在 deepseek v2 时提出的 mla 原理直接沿用到了 deepseek v3 和 deepseek r1 版本上,后来发布的全新注意力架构 nsa 更是实现了超高速长上下文训练与推理。
回到 llama 4 这边,根据ai科技评论的了解,对大模型架构有研究的专业人士认为,llama 4 非常缺乏工艺创新,比如说,在后训练阶段还在死守dpo。而此前的一系列理论和实验都表明 dpo 的泛化能力,“比ppo差得远”。ppo在实际使用中需要调的细节很多,不易上手。在deepseek提出grpo以后,越来越多的研究者开始使用grpo及其改版。 meta 还继续坚持用着 dpo 而不选择创新,这么来看 llama 4 做成如此也属于意料之中。
常人没法用,专家用不着
而最让人失望的是,llama 4 系列的模型都无法放入家用电脑,并且 llama 4 除了一直在宣传的 10m 上下窗口外,貌似已经没有任何优势,而这一点对于大多数人来说其实并不是必需的内容。
除此之外,gpt 4o, gemini 2.5 pro 这些拥有生图能力的模型型号已经正式推出,而 grok3、gemini 2 flash 等多模态模型也已经开始广泛开放,这也意味着更多的人没有再用 llama 4 的理由,或者说,llama 4 本身没有太强的市场竞争力。

反观这次 llama 4 的翻车事件,不难看出其实 llama 4 系列模型很可能是 meta 在追赶大模型潮流的战略布局中的一枚关键棋子,但却因为太过于“急功近利”而选择作弊,导致直接失去了社区的支持,进而失去了自身的竞争优势。
并且 llama 2、llama 3 的时代已经过去,选择 llama 作为基座的开源模型只会越来越少,雷峰网(公众号:雷峰网)认为对于 meta 来说,与其选择作弊刷榜博眼球,不如想想如何创新,如何提高社区适用度,能不能追上最前端的工艺暂且放一边,最关键的是先把口碑先赚回来。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。

下一篇: